What is this document?
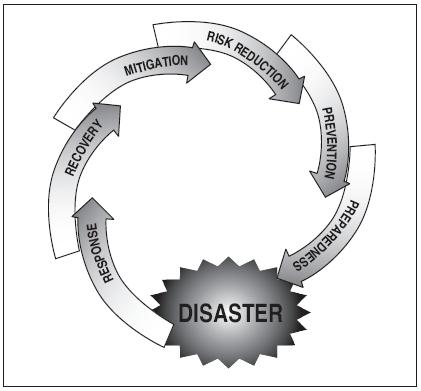
This document describes the set of guidelines that should be followed when a major issue like network failure or total service breakdown happens which causes a lot of failures and alerts. The reason why we need special guidelines for this case is to make sure everyone is updated on a timely manner on what the progress of the issue is and at the same time there is only one point of contact person who is making sure things are fixed in the right order.
First response
When the issue is found for the first time, create a proper ticket in the issue management tool e.g. jira, Integrity, Remedy, by providing as much details as you can. You must follow any template or guidelines layout by your organization. Also, send an email to all stakeholders about the issue.
Continuous Updates
Since it is not possible to provide updates after constant interval, during each update, please mention when the next update will be provided. In addition to updating issue ticket with the update, send the same information in an email.
Owner of the issue
For these kinds of issues, it is important to have only one owner for the issue so that communication is streamlined and there are not too many emails going around from multiple people. This owner is responsible to coordinate efforts with developers and to provide updates to business teams. This owner is also responsible to make sure to convey priorities from business team to developers.
Try implementing the DR
Check if there is any Disaster Recovery solution in place for the effected services. In case the normal service restore will take more than 30 minutes, it is better to invoke the DR solution. Invoking the DR solution will help in normalizing the business and will help in minimal business impact. Once the primary setup is up and running then we must restore the primary services and revert the DR solution.
Work on restore of services
In case of any disaster, your first priority should be to restore the services only. Any deep analysis , testing, etc should be handled at later stages. Deep analysis or excess testing will delay the restoration and will lead towards business and financial losses.
Closure communication
It is very important to send the closure communication of the disaster. The closure communication should be send as last email to the continuous updates you were sending through email. The solution must be documented and must be attached to ticket and copied to ant Wikipedia or knowledge base of your organization with all possible details.
Root Cause Analysis
Root cause analysis is very important for all disasters. This will help in analyzing causes for disaster and help in avoiding the situation in future. Root cause analysis should be documented and copied to ticket, in addition to communicate all relevant stakeholders excluding the end / business users. Root cause analysis should be copied to the knowledge base or any Wikipedia of organization.
Work on permanent fix
You must work on fix the problem that causes the disaster. This will help in avoiding the major service disruption in future. E,g. if the problem comes any service account expiration, then a proper method should be set for all services that have information for all service accounts with all relevant details like, owner, time to renew, who must raise the request, must will follow the request, who must approve the request, to whom to communicate for service account extension , all emails etc.